为project做准备(一个月用完跑路,芜湖)
设置root和password方便远程登录(已写)
然后就是安装软件
因为偷懒,为了方便上传文件,先安装aapanel
aaPanel
1
wget -O install.sh http://www.aapanel.com/script/install-ubuntu_6.0_en.sh && bash install.sh forum
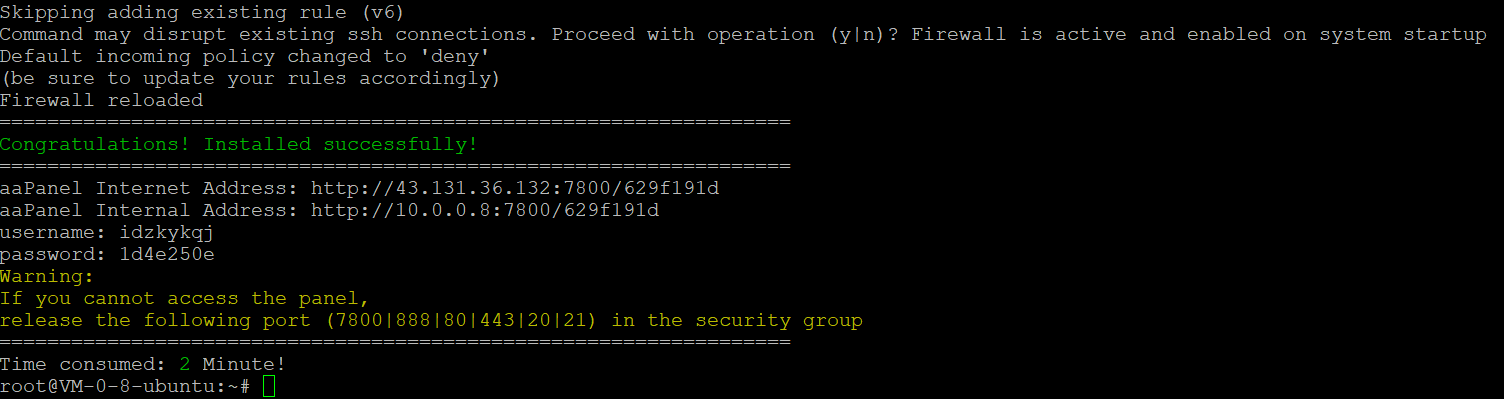
aaPanel Internet Address: http://43.131.36.132:7800/629f191d
aaPanel Internal Address: http://10.0.0.8:7800/629f191d
username: idzkykqj
password: 1d4e250e
要去控制台的security group开放端口!!!
Java
/usr/lib/jvm
tar -zxvf ./jdk-8u162-linux-x64.tar.gz
vim ~/.bashrc
2
3
4
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc
java -version

Hadoop3.1.3
tar -zxvf hadoop-3.1.3.tar.gz
sudo mv ./hadoop-3.1.3/ ./hadoop
sudo chown -R hadoop ./hadoop
到/usr/local/hadoop文件夹,执行
.bin/hadoop version

hadoop文件夹下创建input文件夹
Hadoop伪分布式配置
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
/etc/hadoop/core-site.xml
1 | <configuration> |
/etc/hadoop/hdfs-site.xml
1 | <configuration> |
Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
sudo apt-get install ssh openssh-server
ssh localhost
sudo service ssh start
ps -e | grep sshd
报错
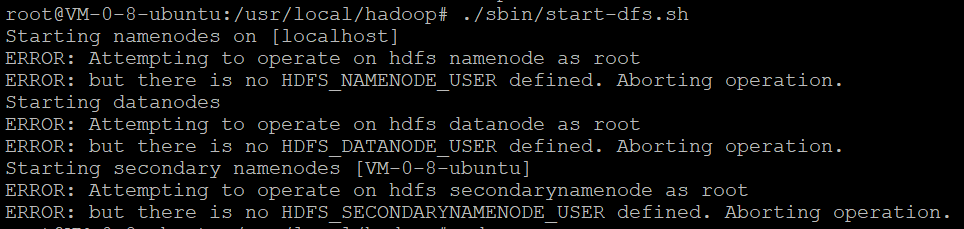
创建Hadoop用户
sudo passwd hadoop
sudo adduser hadoop sudo
sudo apt-get update
切换用户之后
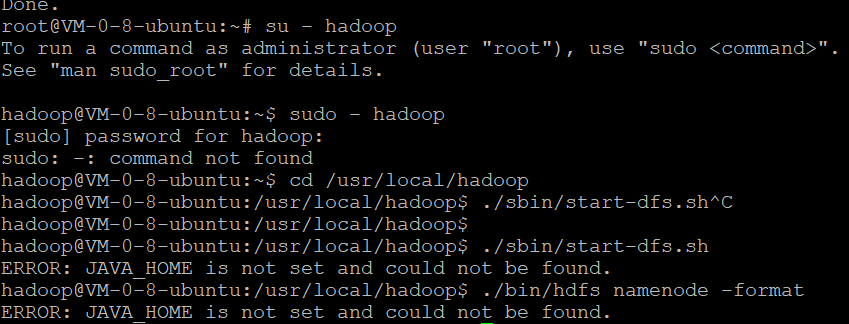
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。如果已经按照前面教程在.bashrc文件中设置了JAVA_HOME,还是出现 Error: JAVA_HOME is not set and could not be found. 的错误,那么,请到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,然后,再次启动Hadoop。
切换用户之后, 需要生成密钥,就可以无密码登录ssh
去.ssh
- cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
- ssh-keygen -t rsa # 会有提示,都按回车就可以
- cat ./id_rsa.pub >> ./authorized_keys # 加入授权
开启守护进程后通过jps指令查看结果
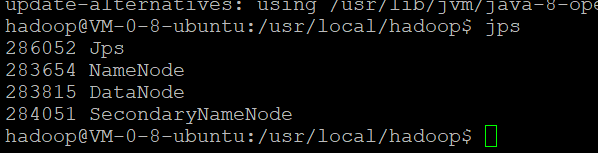
若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
重新格式化 NameNode
./bin/hdfs namenode -format
启动Hadoop
./sbin/start-dfs.sh
关闭hadoop
./sbin/stop-dfs.sh
若是 DataNode 没有启动,可尝试如下的方法(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做)
1 | cd /usr/local/hadoop |
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
1 | ./bin/hdfs dfs -rm -r output # 删除 output 文件夹 |
运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作:
1 | Configuration conf = new Configuration(); |
Spark
压缩文件放到local,解压
重命名
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark
改权限
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
修改spark的配置文件spark-env.sh
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
在spark-env.sh第一行添加
1 | export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) |
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功。
1 | cd /usr/local/spark |
但是执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中)
1 | cd /usr/local/spark |

启动spark shell
bin/spark-shell
退出Spark shell
:q
Python
Spark2.1.0+入门:Spark的安装和使用(Python版)_厦大数据库实验室博客 (xmu.edu.cn)
Anaconda
python3.9
压缩文件保存到 /home/hadoop
安装
bash Anaconda3-2021.11-Linux-x86_64.sh
默认的安装路径
conda初始化(设置环境变量)
reload the shell
必须先关闭终端再打开才有效
exec $SHELL
1 | exec bash |
检查anaconda 版本
这时前面多了个base,指的是当前环境。可以通过
conda config –set auto_activate_base false
关闭
装完anaconda,python也有了

复制粘贴
1,将数据从windows复制到ubuntu:你首先用ctrl+c复制内容,然后在ubuntu的终端下按下鼠标的滚轮。
2,将数据从ubuntu复制到widnows:你首先选中终端里要复制的内容(不要按ctrl+c,选中即复制),然后在windows中按下ctrl+v。
访问服务器的jupyter notebook
ipython
In [1]: from notebook.auth import passwd
In [2]: passwd()
Enter password:
Verify password:
Out[3]: ‘argon2:$argon2id$v=19$m=10240,t=10,p=8$kjPCgB+Ux8SVOHiTxb2peg$0GiCPNnIAdOYH4m6EBYbNA’’
In [3]: exit()
生成配置文件
jupyter notebook –generate-config
修改配置文件
vim ~/.jupyter/jupyter_notebook_config.py
用 / 查找内容并修改注释为以下内容然后**:wq**保存退出即可。字符串前加’u’表示后面的字符串以Unicode格式进行编码,防止因为字符串存储格式不同而导致解析出错。
c.NotebookApp.allow_remote_access = True # 允许外部访问
c.NotebookApp.ip=’*’ # 设置所有ip皆可访问
c.NotebookApp.password = u’sha1:salt:hashed-password’ # 刚才生成的密钥’
c.NotebookApp.open_browser = False # 禁止自动打开浏览器
c.NotebookApp.port = 8888 # 任意指定一个不冲突的端口
c.NotebookApp.notebook_dir = ‘/home/hadoop/jupyterproject/‘ #默认文件路径
c.NotebookApp.allow_root = True # 允许root身份运行jupyter notebook
除了在阿里云官网控制台的安全组中添加相应端口外,还要在云服务器中也相应地开放端口。
sudo su root
ufw allow 8888
ufw reload
ufw status
在hadoop身份下运行jupyter notebook,ip + 端口就可以访问了
Jupyter Notebook 服务器后台保持运行或关闭
后台开
1 | nohup jupyter notebook --allow-root& |
后台关
1 | ps -aux | grep jupyter |
找到PID之后
1 | kill -9 PID |
!PySpark和Spark
Spark: 原生语言为scala
PySpark: 使用了python api对spark进行交互
spark这个框架,基于hadoop,spark是基于内存的(hadoop基于磁盘的)
pyspark是spark用python写的api接口,内存读写速度肯定比磁盘快
配置Jupyter Notebook实现和PySpark交互
http://dblab.xmu.edu.cn/blog/2575-2/
其他技术
Flink ???
Flume ???
优势
Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据.
提供上下文路由特征
Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
具有特征
Flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等
支持各种接入资源数据的类型以及接出数据类型
支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
可以被水平扩展
AWS EKS ???
数据存储
https://aws.amazon.com/cn/ekss
Windows or Ubuntu ? ? ?
winutils
Hadoop节点???
cluster
node
Comment
为了方便spark读取生成RDD或者DataFrame,首先将us-counties.csv转换为.txt格式文件us-counties.txt。转换操作使用python实现,代码组织在toTxt.py中
~/home/hadoop/
1 | import pandas as pd |
Upload “/home/hadoop/us-counties.txt” from the local filesystem to the HDFS filesystem at “/user/hadoop/us-counties.txt “
1 | ./bin/hdfs dfs -put /home/hadoop/us-counties.txt /user/hadoop |
在/usr/local/hadoop这个路径里面
失败了。因为没有user/hadoop
所以这里需要先创建用户目录
1 | e |
2022-04-28 21:19:53,534 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
(这个暂时不管)

没找到在哪,但就是成功了

HDFS文件系统的根目录是/,用户主目录是/user/[hadoop用户名]
HDFS上传文件命令:hadoop fs -put
HDFS下载文件命令:hadoop fs -get
HDFS储存文件目录实在:tmp/dfs/data/current/finalized/subdir0/subdir0/
#tmp是在配置hdfs-site.xml是所配置的文件夹
tmp/dfs/name/current/VERSION下存储DataNode的clusterID
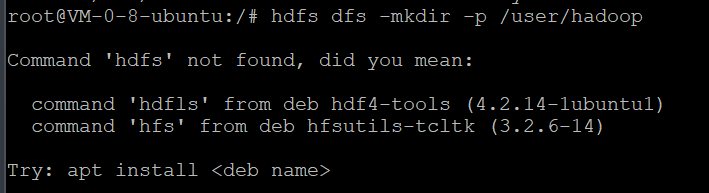
这个就是添加路径
https://blog.csdn.net/Y_6155/article/details/110108809
上述Spark计算结果保存.json文件,方便后续可视化处理
由于使用Python读取HDFS文件系统不太方便,故将HDFS上结果文件转储到本地文件系统中,使用以下命令:
1 | hdfs dfs -get /user/hadoop/result1.json/*.json /home/hadoop/jupyternotebook/result1 |
对于result2等结果文件,使用相同命令,只需要改一下路径即可。
失败
./bin/hdfs dfs -mkdir /user/hadoop/input
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)