“Big_Data_Concepts_Techniques_and_Technologies”
2.1. BIG DATA RELEVANCE
Organizations need to understand and analyze relevant data flows, join data analytics with product/process development, and move it closer to the core business (Davenport et al., 2012).
Possible Applications:
healthcare, public sector, retail, manufacturing, and personal-location contexts, stating that value can be generated in each one of them.
Concept:
The concept of Big Data is about leveraging access to a vast volume of data, which
can help retrieving value for organizations, with minimal human intervention, due to the
advancements made in data processing technologies.
Usage:
- The use of Big Data can make information more transparent and usable across the
organization - Business performance can be increased with more accurate and detailed facts, turned
possible by collecting and processing more transactional data - Better management decisions can be made through data analysis
- Better management decisions can be made through data analysis
Big Data will have a significant impact in value creation and competitive advantage for organizations, such as new ways to interact with customers or to develop products, services, and strategies, consequently raising profitability. Another area where the concept of Big Data is of major relevance is the Internet of Things (IoT), seen as a network of sensors embedded into several devices (e.g., appliances, smartphones, cars), which is a significant source of Big Data, bringing many business environments (e.g., cities) into the era of Big Data (M. Chen et al., 2014).

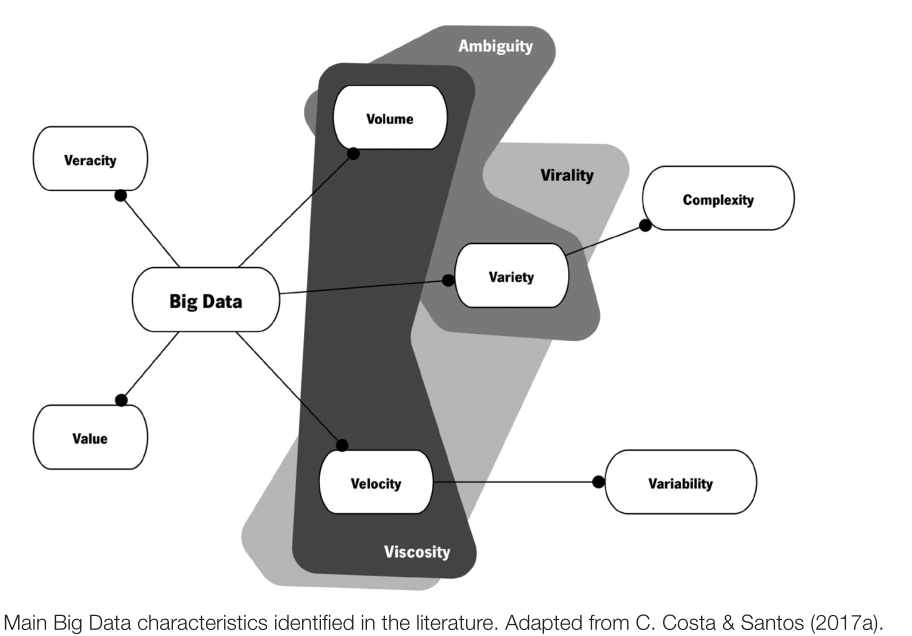
2.2. BIG DATA CHARACTERISTICS
There is no widely accepted threshold for classifying data as Big Data
“big” implies significance, complexity, and challenge
- characteristics
- the augmentation of traditional data with more unstructured data sources
- quantitative thresholds
(size, complexity, or techniques and technologies to process large
and complex datasets.)
Variety:
Regarding variety, Big Data can be classified as structured (e.g., transactional data,
spreadsheets, and relational databases), semi-structured (e.g., Web server logs, Extensible Markup Language – XML, and JavaScript Object Notation – JSON), and unstructured (e.g., social media posts, audio, video, and images) (Chandarana & Vijayalakshmi, 2014; Gandomi & Haider, 2015). Traditional technologies can have significant difficulties storing and processing Big Data, such as content from Web pages, click-stream data, search indexes, social media posts, emails, documents, and sensor data. Most of this data does not fit well in traditional databases, hence, there must be a paradigm shift in the way organizations perform analyzes to accommodate raw structured, semi-structured, and unstructured data, in order to take advantage of the value in Big Data (Zikopoulos & Eaton, 2011).
The final characteristic covered by the 3Vs model is velocity, which refers either to the
rate at which data is generated or to the required speed of analysis and decision support
(Gandomi & Haider, 2015). Data can be generated at different rates, ranging from batch
to real-time (streaming) (Chandarana & Vijayalakshmi, 2014; Zikopoulos & Eaton, 2011).
It is preferable to apply the definition of velocity to data in motion, instead of the rate at
which data is collected, stored, and retrieved from storage. Continuous data streams can
create competitive advantages in contexts where the identification of trends must occur
in short periods of time, as in financial markets, for example (Zikopoulos & Eaton, 2011).

Q:
Hardware / good database
Other characteristics, which according to the literature often go unnoticed, are the variability and complexity, introduced by SAS (Gandomi & Haider, 2015). Variability is related to the different rates at which data flows, according to different peaks and inconsistent data velocity. Complexity highlights the challenges of dealing with data from multiple sources, namely connecting, matching, cleaning, and transforming them. Besides the former, Krishnan (2013) also proposes three other characteristics: ambiguity, concerning the lack of appropriate metadata, resulting from the combination of volume and variety; viscosity, when the volume and velocity of data cause resistance in data flows; virality, which measures the time of data propagation among peers in a network.
2.3. BIG DATA CHALLENGES
General dilemmas may include challenges such as the lack of consensus and rigor in
Big Data’ s definition, models, and architectures.
In fact, the lack of standard benchmarks to compare different technologies is seriously aggravated by the constant technological evolution of Big Data environments
Q:
anyway to set a standard
How to take full advantage of Big Data in areas such as scientific research, engineering,
medicine, finance, education, government, retail, transportation, or telecommunications
remains an open question
Discussions about how to select the most appropriate data from several sources or how to estimate their value are major issues (Chandarana & Vijayalakshmi, 2014).
Another issue regularly discussed is how Big Data helps representing the population better than a small dataset does . The answer obviously depends on the context, but the authors make the important point that one should not assume that more data is always better
Data throughout its life cycle can potentially create severe bottlenecks in networks,
storage devices, and relational databases.
take significant time, as it is challenging to sequentially iterate through the whole dataset in a short amount of time. Consequently, the authors highlight the importance of designing indexes and implementing adequate preprocessing technologies. Hashem et al. (2015) identify the need to study adequate models to store and retrieve data as a crucial factor to successfully implement Big Data solutions. Models and algorithms for scalable data analysis also remain an open research issue, as well as the integration and analysis of data arriving continuously from streams
Mining data streams has been identified as an emergent research topic in Big Data analytics (H. Chen, Chiang, & Storey, 2012).
one of the challenges lies in guaranteeing adequate monitoring and security without
exposing users’ data when processing it.